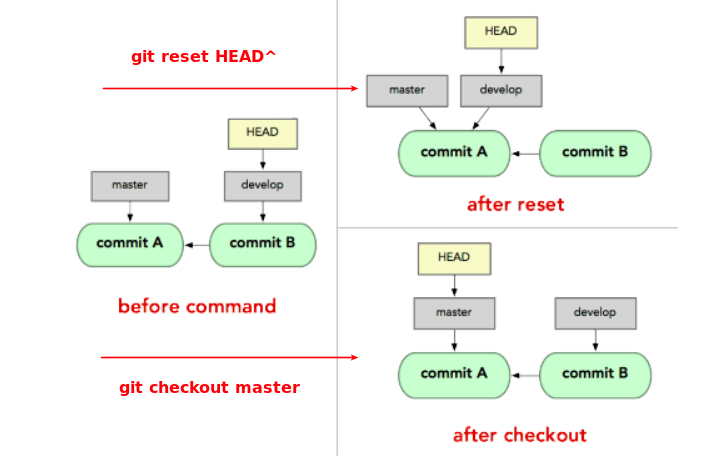
There are many git commands that uses HEAD to operate. Some people say it is a pointer by analogy to the concept in programming language, but this is still vague. There are threads topic 1 topic 2 on Stackoverflow talking about HEAD, it may help us have a better understand of HEAD. However, having more knowledge of git core internals and concepts will make us better understand how git works as a version control tool, and I am trying to understand HEAD by learning more about git internals. Git is indeed a content-addressable filesystem. We can consider the core of Git as a key-value database. This means that you can insert any kind of content into a Git repository, for which Git will hand you back a unique key you can use later to retrieve that content. $ mkdir project && cd $_ # create and enter an empty project directory $ git init # this will initialize an empty database. $ ls -al # and we will find a hidden direcotry named .git .git $ ls -F .git # list the files or direcotries created in .git, including 5 directories and 3 files, and one file name is HEAD. branches/ config description HEAD hooks/ info/ objects/ refs/ $ ls -R .git/objects # and there are two empty folders in ./git/objects/ .git/objects: info pack .git/objects/info: .git/objects/pack: $ echo 'test content' > test $ git add test $ ls -R .git/objects # git add will generate a d6 folder d6 with a file inside it, the filename consitis of 38 digits…
Sunflower
Stay hungry stay foolish
Troubleshoot unstable site access caused by wrong tcp socket recycle setting
Four steps to add Google Fonts in Tailwind CSS
A note-taking of using Webpack 5.x
ESLint & Prettier: Enable semi option without complaints
Understand git HEAD from git internals
Fix XAMPP mysql start issue: /opt/lampp/bin/mysql.server: 264: kill: No such process
Install ipython and jupyter notebook
Implement responsive Holy Grail Layout by float, flexbox or CSS Grid
Build an audio fragments merger with gui for qlive App courses
Ways of Vue components communication and How to use Vuex State Manager
Use sessionStorage to fix page blank issue of F5 refresh due to vue route push params loss
The easiest and fastest way to migrate wordpress blog with LetsEncrypt SSL certificate to GCP
Categories